[フリーソフト] 無料OCRソフト GT Textの読み取り精度は?

それほど頻繁にあるわけではないですが、画像から文章だけを抽出したい事ってありますよね?このGT Textはまさにそんな時に試して欲しいフリーソフトです。
面白そうなソフトは無いものかと窓の杜やVectorを物色していた時にたまたま目についたのがこのGT Textでしたが、そう言えばOCRソフトなんてしばらく使ってなかったけど少しは読み取り精度とかマシになったんだろうか?という事で試してみる事にしました。
OCRフリーソフトの読み取り精度は?「GT Text」を試してみる
気軽に使えそうな感じが良い
スキャナから用紙を読み込んで~とかだったら面倒なので試してみようとは思いませんでしたが、画像をドラッグ&ドロップして読み取りたい範囲を指定してやるだけという手軽さが気に入りました。
このGT Textは画像ファイルからテキストを抽出するという比較的特殊なソフトと言えるので、特に使い所の無い方も多いのではないかとは思いますが、私としては今までにこの機能が欲しい状況が全く無かったわけでもないので、この機会に試してみるのもいいかなと、とりあえずそんなところです。
GT Textのダウンロードとインストール
こちらのサイトからダウンロード出来ます、現在の最新バージョンは2.0.2となっています。

インストール方法についてはスクリーンショット付きで説明が必要なほど難しくは無いと思いますんで、ざっくりとですが簡単に説明させていただきますと
- をクリック。
- 私の場合は自分専用PCなので、下の「Install just for me」を選択してをクリック。
- 私の場合は「Program Files」以外にインストールしたくなかったので変更しましたが、後で※のような記述を公式サイトのどこだったかで見かけたので一応注意して下さいませ。
- スタートアップメニューに追加するのでそのままをクリック。
- すぐに起動するのでそのままをクリック。
という感じです、注意事項としては
※本ソフトを標準のインストール先以外にインストールしていると、言語ファイルを正しく追加できないことがある。
とありました。ただ、これどこに記述してあったのか今は見つけられないんですけど…
確かにこの後で説明する言語ファイルに関してはデフォルトのパスの方にインストールされてしまいましたが、私が使った限りではちゃんと認識してましたし、日本語の読み取りも出来たので動作上は特に問題は無さそうなように思いました。古いバージョンでの話だったのかも?
日本語用データのインストール
ツールバーの下に「eng」と書かれたプルダウンメニューがあるので、その右の「Add languages」をクリックします。

ポップアップした画面にツリービューがあるので、その中から「Download and install Japanese language data」という項目を探してチェックを入れ、をクリックします。
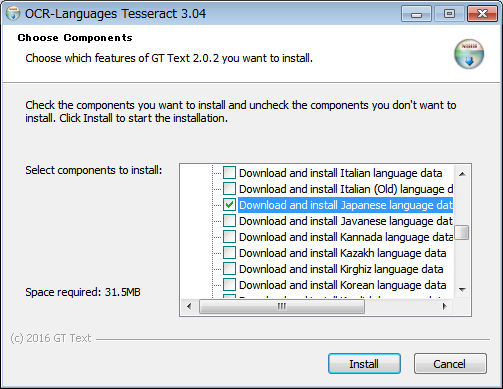
尚、このデータは日本語ファイルと言っても、アプリのメニューやダイアログを日本語化してくれるわけではなく、日本語の読み取りに使用するデータになります。
UIはお世辞にも良いとは言い難い
最近はフリーソフトでも「ホントにこれ無料のソフトなの?」と聞きたくなるくらいUI(ユーザーインターフェースの事です、念の為)が良く出来ているものも多いので、そういったソフトに比べると若干見劣りはしますが、読み取りの精度さえ良ければとりあえずそんなものは問題ナッシンでしょう。
GT Textの読み取り精度は?
当然、英語に比べたら日本語の方が複雑で読み取りは困難だろうというのは予想出来ますので、まずは英語で軽くテストしてから日本語を試してみたいと思います。
英語の読み取り精度
それではサンプルとしてWordPress.orgのトップページの一部を読み取らせてみます。日本語ファイルの追加がうまくいっていれば読み取り言語を「jpn」と「eng」から選択出来るようになっているはずですが、今は「eng」に設定しておきます。
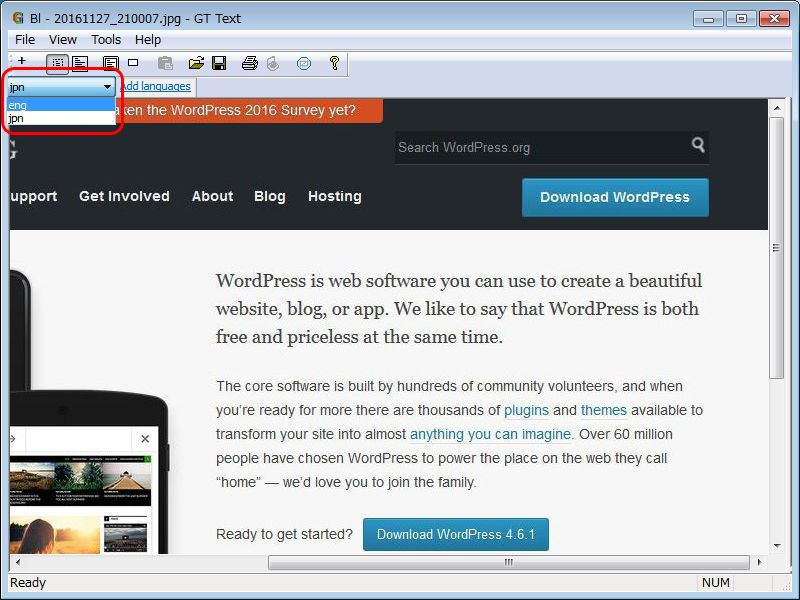
次にテキストの読み取り範囲を指定します。読み取らせたいテキストの開始位置でクリックしたまま対角線上にドラッグして終了位置で離すと自動的に読み取りが始まります。

読み取りが終わるとダイアログに結果が表示されます。それにしても短い文章とは言え一字一句の違いもありません…すばらです。日本語に比べたら英語は元々読み取り精度が高いですが、それでもこの結果は素直にスゴイと思いました。

結果がOKならここでをクリックするとクリップボードにテキストがコピーされるので、そのままテキストエディタなりに貼り付ける事が出来ます。
日本語の読み取り精度
次は日本語の読み取りを試してみたいと思います。こちらはサンプルとして当サイトの投稿リストのスクリーンショットを撮影して、それを読み取らせてみました。やり方は先ほどと同様ですが、今度は言語を「eng」から「jpn」に変更してからテキストの範囲を指定します。
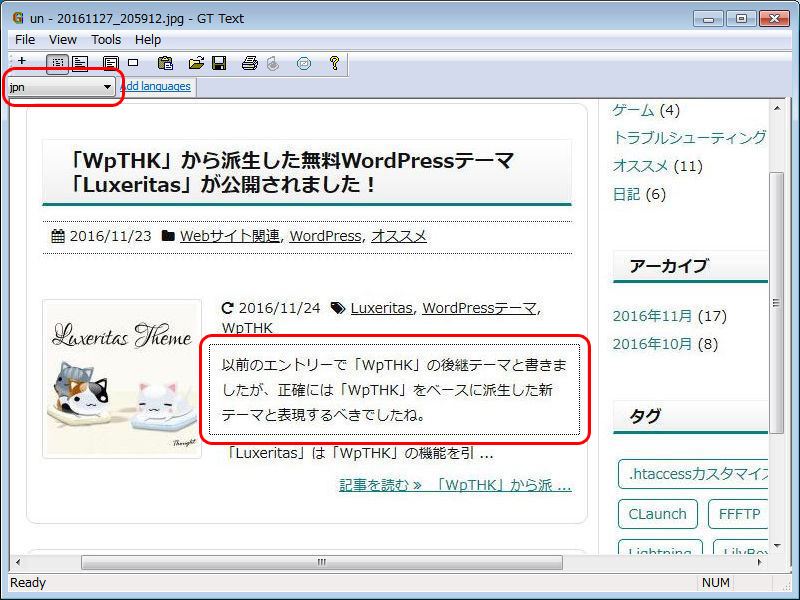
一瞬「おぉぅ?!」と思いましたが、よーく見ると「エントリー」が「エシトリー」に、「書きました」が「喜きました」になっています…惜しい、非常に惜しい。しかし良い意味で私の予想の遥か斜め上を行く読み取り精度です。

もしかしたら文字が大きくなればその分読みやすくなるんじゃね?と思い、今度はブラウザ側である程度まで文字が大きくなるよう拡大してから撮ったスクリーンショットを読み取らせてみました。

さて、これだけ文字が大きければ…

「エントリー」の部分は直りましたが、今度は「書きました」が「害きました」、句読点の「、」が「ヽ」に、「現」が「王見」に分割されてしまいました…どうやら文字が大きければいいってもんでもないようです。
とりあえず二回分の実行結果をテキストエディタに貼り付けてみました。

試行回数は少ないですが、これだけ出来れば及第点と言ってよろしいかと思います。むしろ個人的には全く期待していなかっただけに予想以上の結果となりました。
意外と悪く無いGT Textの読み取り精度
フォントによる可読性の差はあると思いますが、英語の読み取り精度に関してはほぼ実用レベルと言っても良く、日本語に関してはまだまだ改良の余地はあるものの手打ちよりはずっと良いのでは無いかと思いました。今回のテストで使用した程度の文章量なら自分で打った方が早いでしょうけど、作業量によってはこのGT Textを利用してみてもいいかもしれません。
読み取り精度を向上させる為の工夫は必要
少しでも読み取り精度が高くなるようフォントの種類やサイズを変えてみたり、一気に長い文章を読み取らせようとせず文節ごとに細かく分けてみる等の工夫は必要かと思います。
画像ファイルや紙媒体からテキストファイルを作成するような事はそれほど頻繁には無いでしょうが、今後どこかで役に立つ場面もあるかと思いますので、当エントリーで紹介したGT Text以外のOCRソフトも時間を作って試してみたいと思っています。